Chapter 7 Intermediate GitHub
This chapter forms the basis of the Intermediate GitHub training. In this, we will cover some more advanced features of GitHub that you may want to use on occasion. This includes admin tasks like sorting and protecting your repositories, but also fun stuff like setting up GitHub hosted webpages, automating your GitHub behaviours, and making yourself a GitHub homepage.
7.1 Searching in GitHub
GitHub searching is much more powerful than most people realise! As you start getting more comfortable with using it, it allows you to treat our organisational repositories as a code library, and you can easily find examples of how other people have achieved specific tasks or have made use of new functions.
You can search by both repository and organisation, both using the search bar at the top of the page.
7.1.1 Searching by organisation
If you click on the search bar from the Department for Transport GitHub page, the bar will autofill with a organisational search:
org:department-for-transport
This means that, by default any search you do will only look across DfT repositories. This is a bit more restricted than searching the whole of GitHub, but is generally really useful because you:
- know the code works on our systems
- know it’s using an approach that’s suitable for the data we hold
- can track down the person who wrote it and ask them a bunch of questions about their code!
You can then search using plain text and/or GitHub’s search filters.
Plain text works like a Google search. You can type in any full or partial word, and the search will return any instances of that word it finds. The search checks across all the code inside repositories, but also documentation like READMEs, and GitHub features like issues, pull requests, etc.
For example, you could try searching for:
- “line chart” to return examples of code which contains examples of people creating line charts
- purrr::map to see examples of people using this specific function
Search filters provide additional information to the search to narrow it down by author, coding language, topic, etc. They are always written as filter:value, e.g. to search for repositories written in R you would use language:R. You can add these directly to your search query if you know the GitHub syntax, or once you’ve done your search, a graphical interface showing the different filter options will appear for you to interact with.
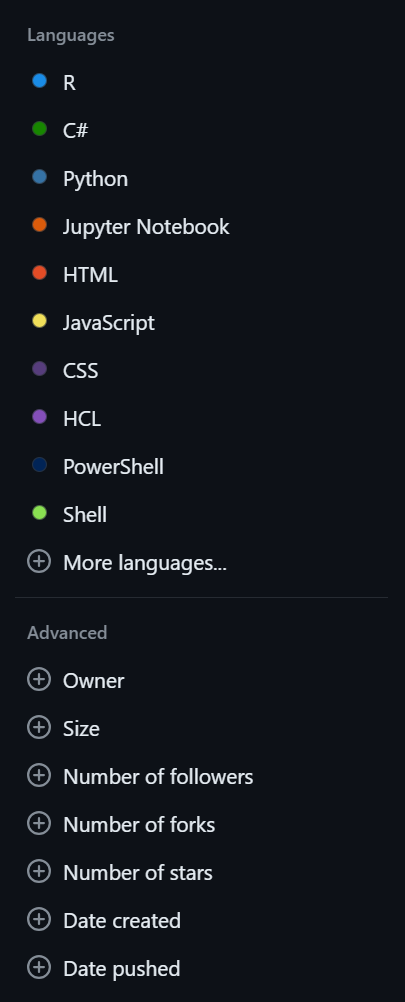
For example, you could apply filters to:
- Only search for code written in Python
- Search through repos created in the last year
- Look only in repositories tagged with the DfT tag “RAP”
You can combine multiple filters and plain text queries in a single search, just separate them with a space. e.g. org:department-for-transport language:r "line chart" searches through DfT repos written in R for examples of code containing about line charts.
7.1.2 Searching by repository
If instead of using the search on the main DfT page, you first navigate to a specific repository, the default search behaviour is instead restricted to the content of that repository alone e.g.:
repo:department-for-transport/transport-in-numbers
Again, this is more restricted, but ideal for searching through a repository to find a specific instance of using or defining a piece of code, or looking to see if a specific problem has been reported (or resolved). As for organisational searches, you can use both plain text and search filters to narrow down what you’re looking for.
7.2 Powerful dots
The “three dots” option next to every line of code in GitHub is one of the lesser known features, but it offers an incredibly powerful range of features which are particularly good when it comes to finding, sharing and solving problems.
To use them, open any code file in GitHub. Next to each line of code, there is a number; if you click on that number, three dots ... appear to the left of the number. Clicking on those dots bring up a menu:
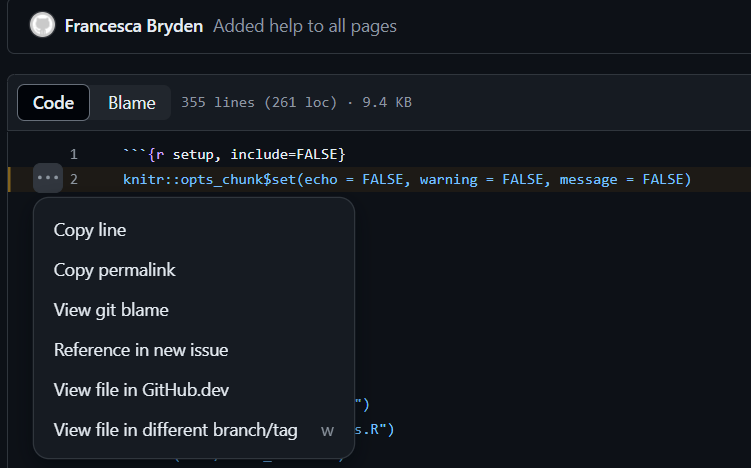
There are a number of different options available in that menu; we’re going to look at just a couple of them.
7.2.1 Code permalinks
A permalink, as the name suggests, is a permanent link to a particular line or section of code. The content of the link persists even after you’ve made changes to your main codebase, which is handy if you’d like to share a link to some broken code but also want to fix that code asap!
To create a permalink to a single line, click the three dots and then “Copy permalink”. To create a link to two or more lines of code, click the starting line number, hold your Shift key, and click the end line number. You can then click “Copy permalink” to generate a link to that whole chunk.
Using permalinks within GitHub has a cool additional feature; including a permalink within an issue or pull request will automatically show the permalink as a little preview window of the code. This makes it very simple to include examples when you’re raising a problem or closing one.
7.2.2 Git blame
Git blame is a handy feature for tracking down the potential source of any new code errors (and/or blaming the person who made them!). Rather than showing code one commit or pull request at a time, it shows the entire code base and the last time it was changed.
To view the git blame for any code file, click the three dots and “view Git blame”. This then shows the code in a new format:
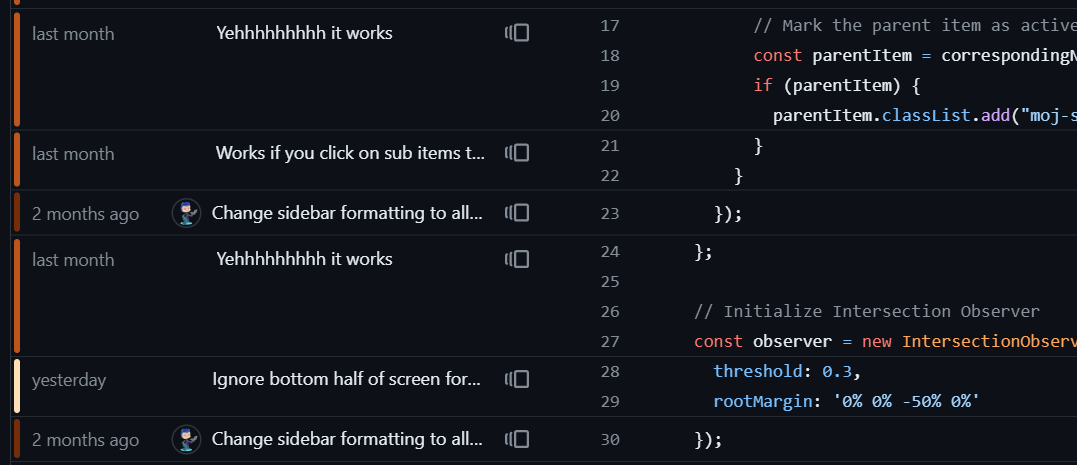
On the left, a colour heatmap gives a quick indication of how recently each line of code was updated. The more bright/yellow the bar, the more recent the last change was. The next column specifies exactly when this last change happened, while the one after that specifies exactly which commit this was. This is a great way to see at a glance which changes were made when, see the associated commits, and generally get to the root of a problem which has recently occurred.
7.3 Forking repositories
7.3.1 What is forking?
“Forking” within the context of GitHub refers to the act of creating a duplicate copy of someone else’s repository. This process grants you the ability to modify a copy of their codebase, making alterations to better suit your needs and application. The changes you make by default won’t affect the original repo
There are a range of scenarios where forking a repository could be useful:
Forking allows you to experiment with the functionality present in the repository. This allows you to assess how well these features meet your project’s needs in this new context.
You might find an existing package or project which meets 90% of your requirements, and needs some minor and specific changes to fully meet your needs. Forking gives the flexibility to make these alterations without changing the original project.
Forking is ideal when you want to expand on someone else’s codebase. By creating a fork, you can use it as a foundation to further develop and refine the functionality, even if you don’t own the original code.
If you spot issues or areas for improvement in someone else’s code, you can make use of a fork to suggest them. You can alter the forked repository to address any issues or introduce new features, and then submit these changes as a pull request to the original repository for review and potential integration.
It’s important to note that a forked repository contains limited features and functionality by default in comparison to a new project. For example, issues, project boards, etc will be turned off, and you can’t fork again from a forked repo. Forks are best treated as long-term temporary extensions of the parent repository.
Do check out the forking chapter if you’d like to learn more technical details!
7.3.2 How to do it?
While on the page of the repository you want to fork, click the “fork” button at the top right of the page. This will show you a list of existing forks, and also gives you the option to “Create a new fork”.
Once you’ve clicked this, you can select the owner of the forked repository. This can be you or an organisation that you’re part of; while at work you’ll normally select the department-for-transport organisation to be the owner of a forked repo you create. You can also set a name for the repository and add a description if you’d like.
Finally, you can choose whether to fork all branches or just the default branch. Which one you choose depends on your future plans for the repository, if you’re taking a “fork and pull” (see below) approach you will probably just want the default branch, whereas for other applications you may want to copy all branches.
Click “create fork” and you’re done! Note that you can’t choose the visibility of your fork like when you set up a new repo; forks always inherit their visibility from their parent repo, and this can’t be changed without changing the parent repo visibility.
7.3.3 Fork and pull
A particularly cool application of forking is making improvements to code that you don’t own. You can use this for any public repository, or internal ones within DfT. The process is similar to creating a branch on a repo you do own, but uses a fork instead:
Create a fork as described above, only forking the default branch of the repository.
Just like when you branch in a repository, make and commit your changes directly to the single branch of the fork you own.
When you’re ready to bring those changes into the original version of the repository, create a pull request. This is the same as a normal pull request, but instead of merging branch-to-branch, you merge repo-to-repo. Here you select not only the branch you want to merge, but the repository as well.

Fork and pull approaches are particularly useful if you are suggesting a fix for a problem you’ve found in someone else’s code. You don’t need to be given editing rights to the original code, and you can make changes and suggest that they be merged into the old codebase at your own pace.
7.3.4 Exercise
- Make your own fork of the repository here: https://github.com/department-for-transport/git-and-github-training
- Make yourself the owner of the fork
- Fork across all branches; you’re going to use this for later tasks!
7.4 Resolving merge conflicts
7.4.1 What is a merge conflict?
If you’ve been using GitHub all this time and never come across a merge conflict, congrats, you’re a wizard!
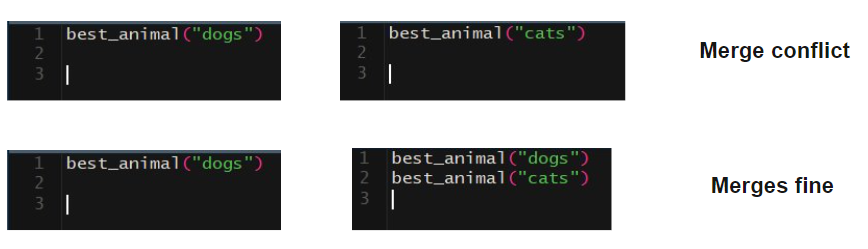
A merge conflict occurs happens when two different branches in Git have made conflicting changes to the same part of the same file or code block, and Git is unable to automatically reconcile those changes. Instead, it records this as a merge conflict and provides an interface for you to make an intelligent decision about which changes you want to keep.
Note that the changes have to be made on the same line for a problem to occur; changing two different lines in two different branches won’t cause a conflict.
7.4.2 Preventing merge conflicts
As with many coding issues, the best way to cure a merge conflict is by never getting one in the first place. Most GitHub good practice is focussed around making sure that you don’t cause merge conflicts, and if you do, they’re quick and easy to resolve.
- Create branches for features, not people, and stick to them!: Branches having specific aims and purpose streamlines the number of files that will be edited in a single branch, and reduces the chance that multiple branches will edit the same file.
Making files shorter, self-contained and well-labelled reduces the risk that someone will change code unintentionally or as part of another task.
Thinking “ooh while I’m on I’ll just clean up our libraries” is a great way to create merge conflict, because you’re editing commonly edited lines. Only do tasks that are relevant to the purpose of the branch. If you need to do a general code clean, do it when all other branches are inactive.
Sticking to single purpose commits, regular pushes, and purposeful pull requests makes it easier to untangle merge conflicts when they do happen.
Keeping your local code up to date with your remote code reduces the risk of conflicts when pulling; these are harder to resolve than conflicts within the GitHub interface!
7.4.3 Resolving merge conflicts
Sooner or later, even with the best practice in the world, you will run across a merge conflict, and you’ll have to resolve it.
The first thing to do is DON’T PANIC. A lot of people will see a conflict and try deleting the file in question; this actually makes the whole conflict much worse, so take a deep breath and follow the process.
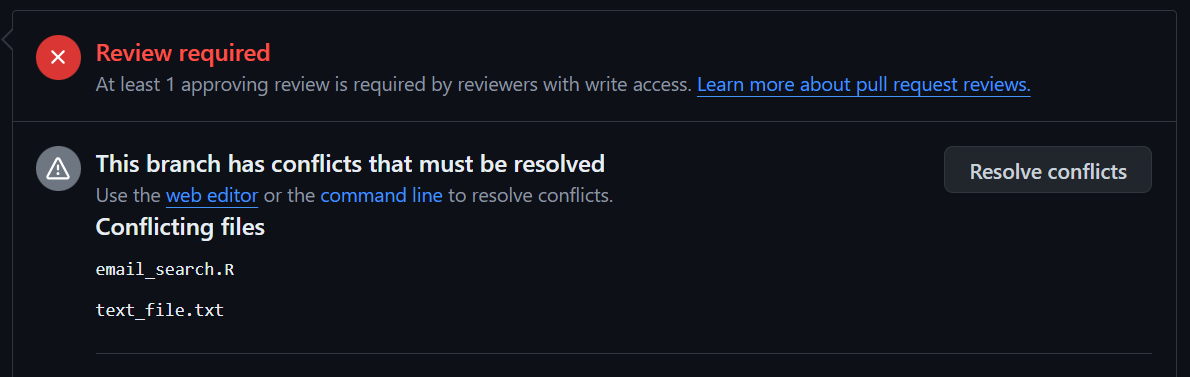
Navigate to the pull request, and scroll down to the merge box. You’ll see a message saying that there are merge conflicts. 90% of the time, you’ll be lucky and the message will say that you can resolve the conflict in the web editor:
7.4.3.1 Resolving conflicts in the web editor
Clicking “resolve conflicts” takes you through to a nice interface where you can see your merge conflicts. Conflicts are marked in the text with three sets of icons:
<<<<< [branch 1]
Everything in here is the code associated with branch 1
======
Everything in here is the code on the same lines in branch 2
>>>> [branch 2]The left arrows indicate where the conflicting lines start, and the right arrows indicate where they end. The row of equals in the middle indicates the change point. The branch names after each set of arrows indicate which set of code is which.
To work with this, use the GitHub interface to navigate to each conflict one at a time. Read the markup and the code to understand what the problem is, and decide what you want to keep. This could be the code from one of the two branches, all of it, none of it, or somewhere in between.
Once you’ve decided what to keep, delete the code you don’t want and delete the markup symbols. Your code should look exactly how you’d want it to look inside the file. E.g. for the code above, I’d want to edit that to simply:
Everything in here is the code associated with branch 1
Move on to the next conflict. When no more remain in that file, mark it as resolved. Repeat this for every file, then commit to save your changes to the branch you’re merging in.
You will then be able to merge the branch in as normal!
7.4.3.2 Resolving conflicts in the command line
Oh no.
On very rare occasions, you’ll see a message that you’re unable to resolve a merge conflict in the web interface. This almost always happens because in one of the branches you’ve made some changes to a file, and in the other you’ve renamed or deleted it (which is why deleting files makes merge conflicts worse).
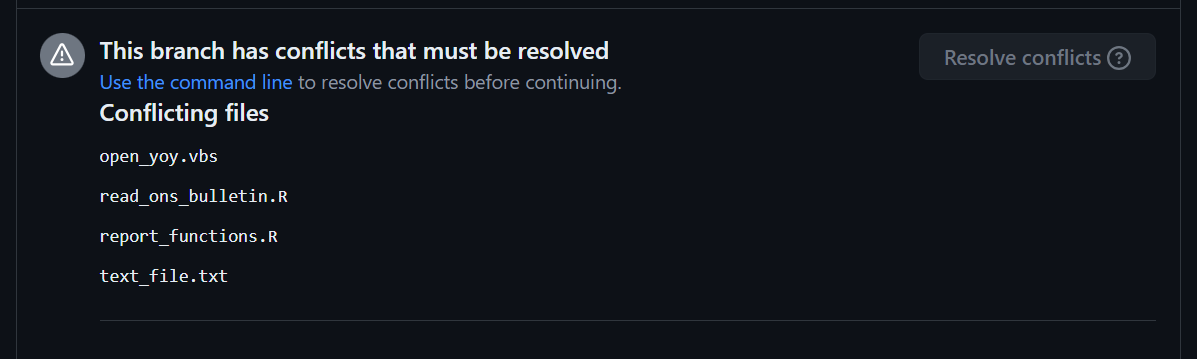
Luckily, GitHub tries to talk you through this as much as possible. Click “use the command line”, and you’ll receive a list of instructions to put into your command line editor (git bash or the R Studio terminal). Start by closing your project, and then reopening it on your default branch. Check that you don’t have any unpushed changes on this branch.
Then open your command line editor, and one line at a time, copy and paste those commands into it, and hit enter to run each one in turn. When you get to step 4, you need to identify the files with conflicts, and open them up. Each one will show markup identical to the previous step, and you need to resolve it in the same way.
Resolve each of your merge conflicts, then commit and push the changes back up.
7.4.3.3 Even harder merge conflicts
You thought it couldn’t get worse than that? It can always get worse. You can find yourself in situations where resolving a merge conflict can actually undo changes you need (usually as a result of back-merging), or you experience merge conflicts as a result of differences between your local and remote branches (sometimes on top of branch conflicts).
These circumstances are very rare, and with good GitHub practice you should never experience them. If you do, ask for help. There are no prizes for GitHub bravery.
7.4.4 Exercise
In your forked repo:
- Set up a pull request from the branch
merge_conflict_exampleto the branchdev - This will automatically produce a merge conflict
- Resolve the conflict in the web editor!
If you feel really brave:
- Set up a pull request from the branch
mega_merge_conflictto the branchdev - This will automatically produce a merge conflict which cannot be fixed in the web editor
- Follow the instructions to fix the problem in Cloud R terminal/git bash
7.5 Setting branch protection rules
7.5.1 What are branch protection rules?
As a default, anyone with the right access can do pretty much anything to your repo:
- Merge their changes into main or dev branches without code review
- Never remove stale feature branches
- Push all their code-breaking changes directly into your live code
- Delete your main code branch
- Merge into the wrong branches
Branch protection rules allow you to restrict when and how people are able to merge branches in, set redundant branches to automatically delete, and prevent people from deleting important branches; preventing Git Anarchy!
7.5.2 Protecting your main/dev branch
The easiest branch protection to put in place is also the most essential! Most people never want their main or dev branches to be deleted, especially by accident, but it’s simple for anyone with admin access to do so!
Branch protection rules can be added by going to settings -> branches. This section of your repository settings gives you the ability to set a wide array of protection rules to any branches you specify.
Start by clicking add rule, which opens a new screen:
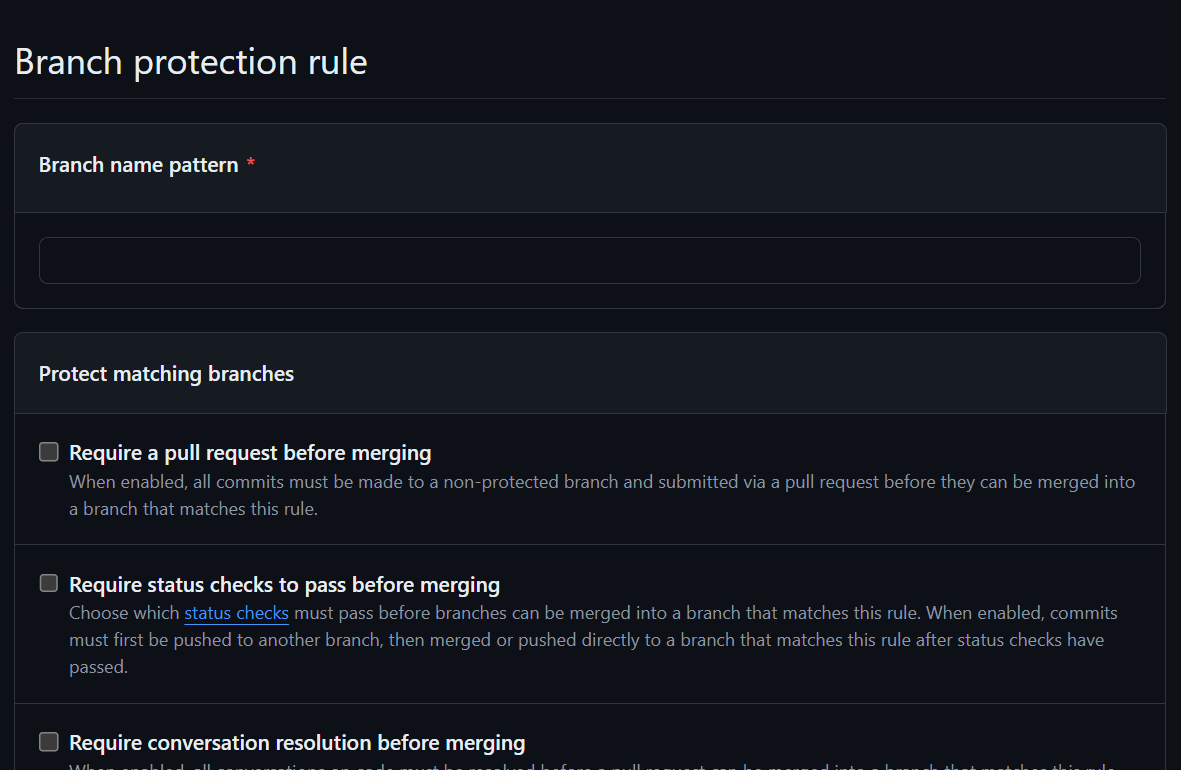
Specify the name of your branch in the “branch name pattern” box. This will actually apply to any branches which contain this string, which is why it’s important never to name feature branches anything that includes the words “main” or “dev”.
Below this, there are a wide range of protection rules that you can apply to your branch, and we’ll discuss a couple of these in the next section. If you don’t select any of these options, you’ll create a basic branche protection which only prevents deletion of the specified branch.
I’d recommend you do this twice, once for each of dev and main.
7.5.3 Adding other rules
While you’re adding protections to your main and dev branch, you can also select other protection rules. These allow you to limit pretty much anything, from insisting that people have committed in a specific way, to ensuring that only certain people can push to that branch.
For good quality coding without a big admin burden, we recommend 2/3 rules as standard for every repo on your main and dev branches:
People won’t be able to push their changes direct to main or dev branches, instead they’ll need to do a pull request and merge their changes in from another branch.
Set by default when you choose to require pull requests: insist that every pull request is checked by a second person before it’s brought into dev or live code.
By default, your repo administrators can bypass the above rules. This is often handy to fix problems quickly, but does encourage lazy coding from them!
7.5.4 Simplifying code review and cleanup
On top of branch protection rules, there are a couple of options you can set in your “general” settings which make code reviewing more streamlined and ensure you’re not left with redundant feature branches after merging.
Whenever a code reviewer approves some changes, automatically merge them in. This saves the original person having to go back in and hit “merge”.
Once a branch is merged in, delete the old branch to keep your repo tidy. You can always undo this if you need to, but generally it’s a very handy feature!
7.6 Releases
7.6.1 What are releases?
As you already know, GitHub saves every single commit you make, so you can always go back to your repository at a specific point of time. However, finding the specific commit state you want from thousands of commits can be tough!
Releases make this process easy, producing a named snapshot of your code at a specific moment in time, allowing for easy comparison and rollback
Releases are ideally suited for code that you’ll use at regularly defined intervals (e.g. publication schedules), or for major milestones in your code (e.g. the version you shared with your stakeholders).
The release numbering and tagging system allows you to easily view the exact code used at that point in time, and you can also add comments to your releases to make them easy to find and identify.
7.6.2 Viewing releases
You can view and create new releases in your repository via the “releases” section on the right had side of your repository:
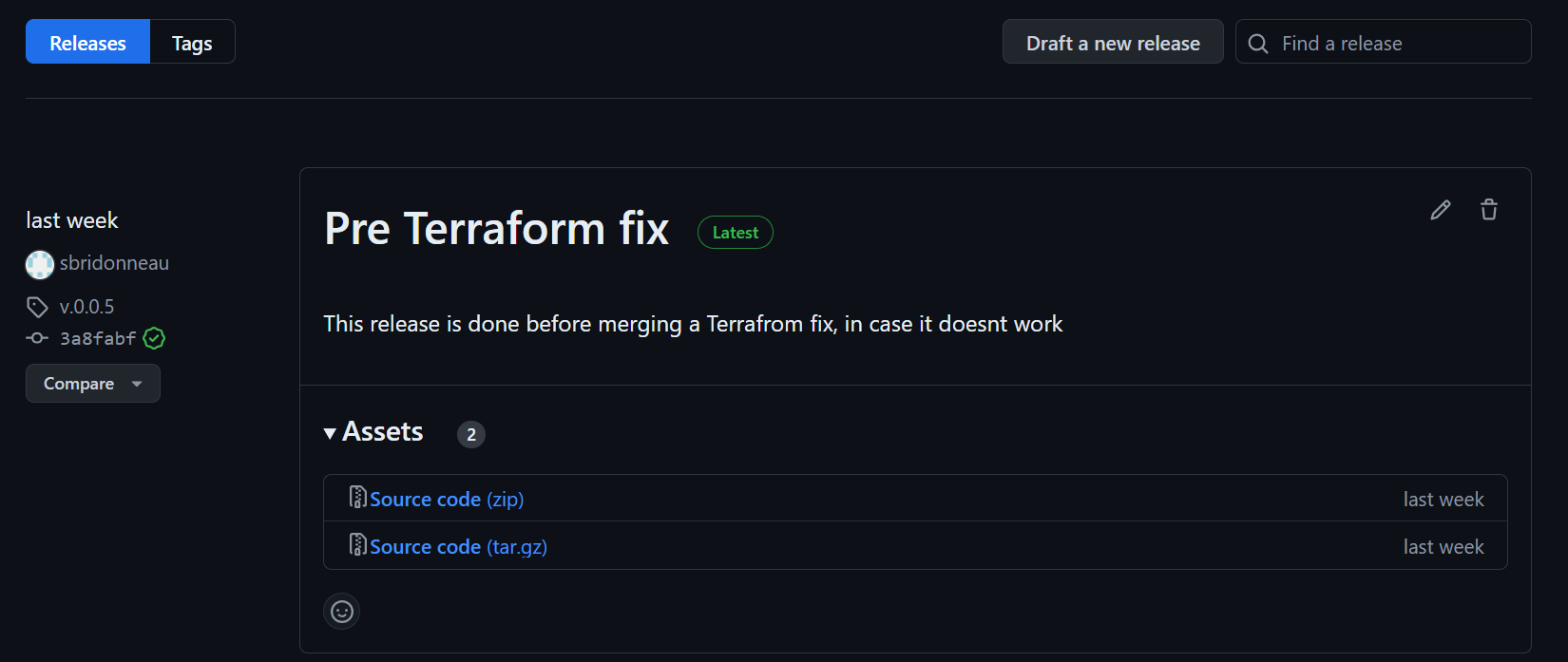
All of your releases are ordered chronologically. At a glance, you can see:
- the release name
- the commit number and branch its associated with
- who released it and when
- the notes associated with the release
- the option to download an archive copy of the code
7.6.3 Creating a new release
You’ll want to create a new release when there’s a significant update to your code that you might want to reflect back on; maybe a significant new feature, or a regular monthly update.
To create the new release, click Draft a new release at the top of the page. This takes you to the release form:
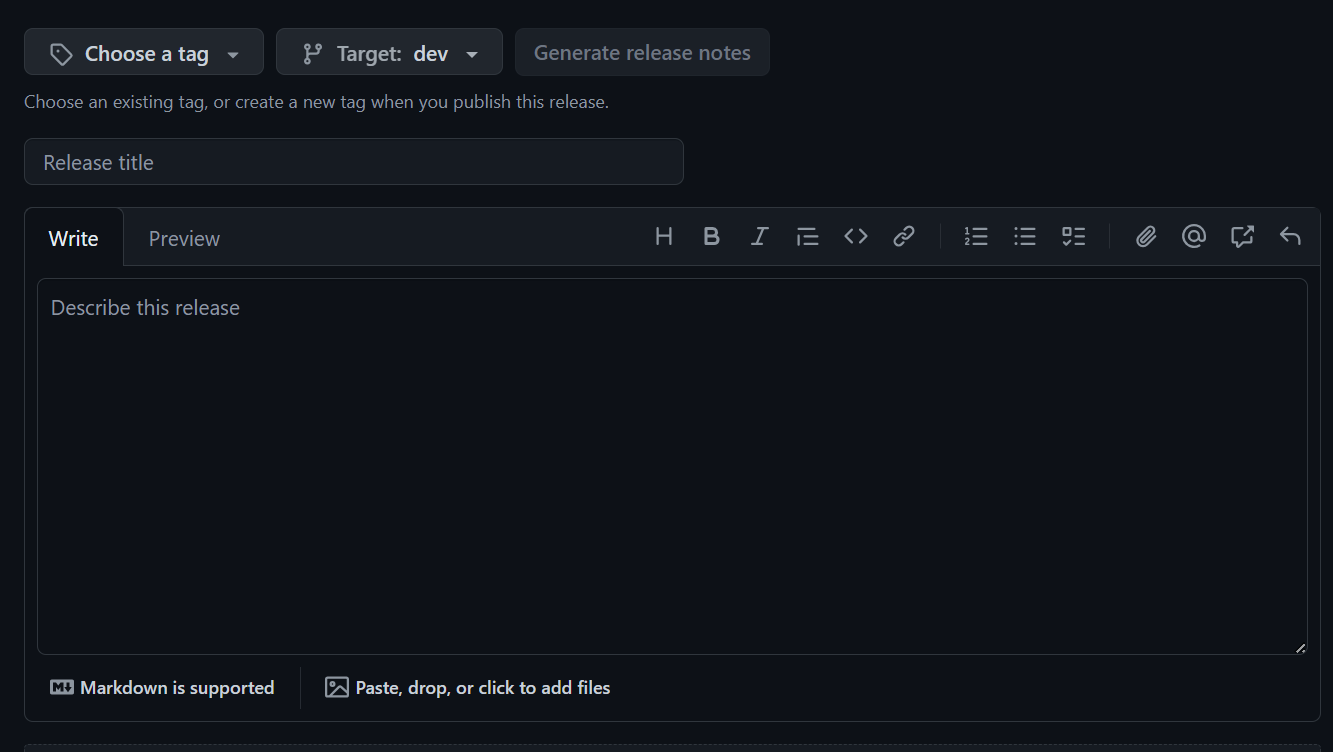
Here you need to:
Give it a clear, descriptive name that will make it easy to find!
Click “tag” and type a numeric tag into the box. This should start with “V” and be sequential from the previous tag, e.g. if that was v0.0.4, you will want to be v0.0.5. Once you’ve typed the tag be sure to click create new tag at the bottom of the list.
It will default to your default branch if you don’t change this.
You can write these yourself based on the purpose of the release, or auto-generate them from the PRs associated with the release.
Don’t mark your release as a pre-release!
And that’s it, you can click publish release to finish.
7.7 Creating a repo template
7.7.1 Why create a template?
Like any other aspect of your analysis, you probably have minimum standards for your code and its documentation. Setting templates allows you to specify details of all of your team’s repositories without a lot of work on their part. This includes things like:
What branches you start with
Standardised structure of folders in the repo
A custom gitignore to make sure they don’t accidentally upload specific file types
Standard issue templates to gather all the information you need when there are problems
Standard PR templates to ensure your code reviews happen the way you need
7.7.2 How to make a template repo
Create a new repository and give it a name that makes it clear it’s a template repository. Set up your template repository exactly how you like it; add a folder structure and modify the gitignore.
You can also set the issue and PR templates in the .github folder; these are plain text templates found either directly in this folder (in the case of the pull request template) or inside the issues subfolder (for the issues template). You can open these .md files on your local computer, or directly in GitHub, and make any changes you want to the file. It uses normal markdown syntax, so you can add things like images, checkboxes, etc.
Unfortunately, you can’t add template branch protection rules etc to a template, these will always have to be set once the repository is created from the template.
Once you’re happy, in settings under the repository name, you can select “template repository”.
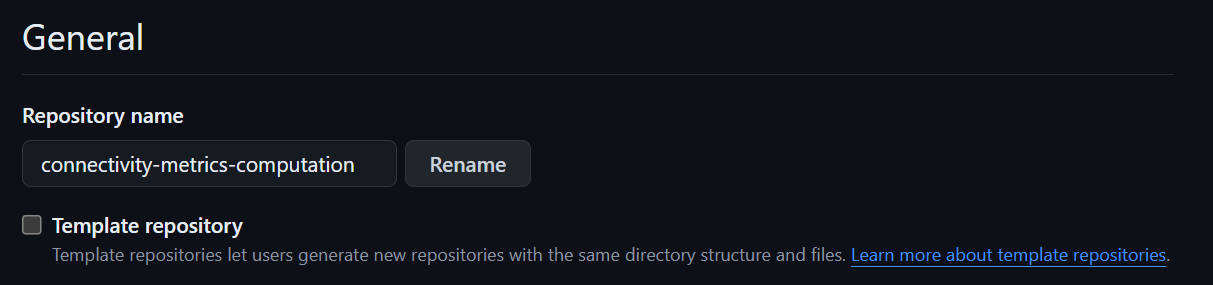
Users can then choose your template from a drop-down list to automatically create any new repository based on it.
7.8 GitHub Pages
7.8.1 What are GitHub Pages?
Although it’s not widely advertised, every GitHub repo has a “pages” option associated with it. These can host any kind of static webpage, created in HTML or markdown, with the underlying code for these pages stored in the associated GitHub repo.
HTML content can be produced directly, or created through Rmarkdown, and includes any kind of Rmarkdown HTML output; reports, visualisations, books, web pages, etc.
Example of the kind of content that can be hosted include:
7.8.2 How to create a GitHub Pages site
Essentially, GitHub can do most of the work with this, as long as you provide it with a few key bits of information.
To start, you need to have a branch on your repository which includes either:
- An index.html file or
- A readme.md document
If you have both, GitHub will default to hosting the index.html file. In either case, you can have additional HTML/md files which are linked to from the one specified, but the index or readme.md file must always be present.
If your HTML files are generated from one or more Rmd files, these can also be created within GitHub Actions; see the next section for more details.
Once you’ve got the documents to be hosted, the rest is done through the pages settings. Navigate to Settings -> Pages, where the page should look like this:
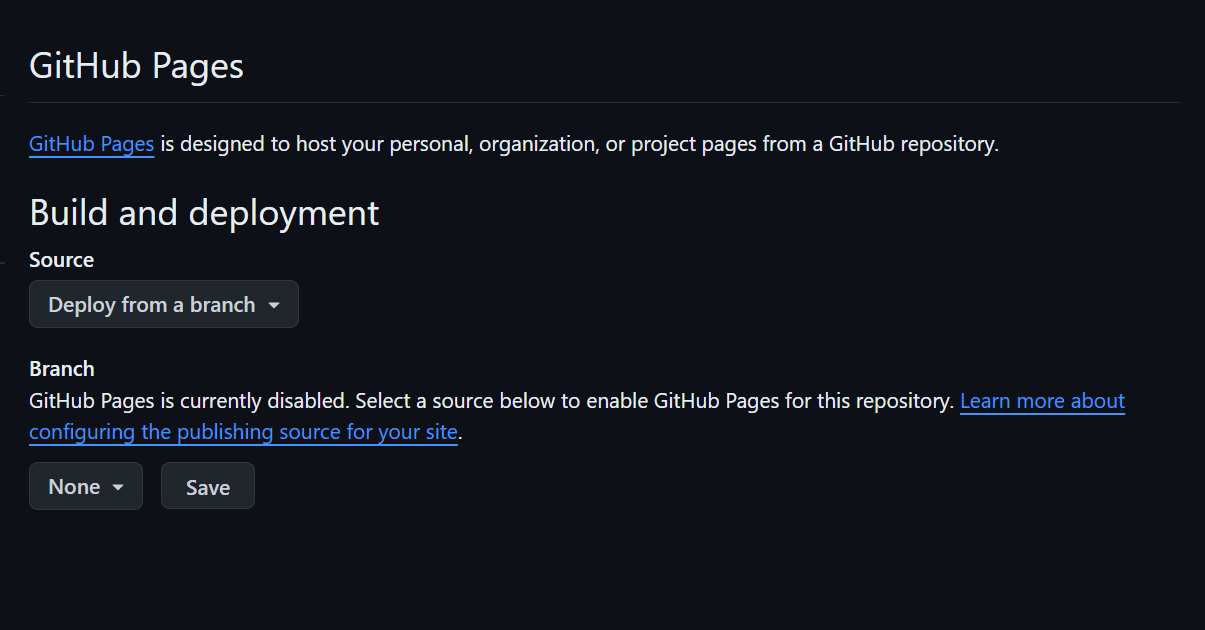
In the “branch” section, choose the branch you want to deploy from (this will usually be main or a pages-specific branch). You can then also select the directory; root means that the file isn’t in a folder, otherwise it is convention to store it in a docs folder or similar.
You can then select the visibility option for the pages. You have two options, private or public:
Is visible only to people who have viewer rights or higher on a repository. The URL for the page will be automatically generated (usually a combination like fuzzy-spoons and random numbers).
Is visible to everyone, including members of the general public. The URL for the page will be defined by the name of the repository (i.e. department-for-transport.github.io/name of repository).
If in doubt, always select Private. Unfortunately, there is no “internal” setting for pages like there is for repositories.
That’s it! An action will automatically engage to deploy the page, and it will build and deploy the page within a couple of minutes. The settings page will also update to give you the URL of your hosted page.
7.8.3 Exercise (to try later)
- In your fork, find the
index.htmlfile - Go to the pages tab and publish the
index.htmlfile as a page. Make sure you have specified the right branch and file location. - The pages tab should change to say your page is being built; you can track its progress in the actions tab if you like!
- Navigate to your page once it has finished building to view the output
7.9 GitHub Actions
7.9.1 What are GitHub Actions?
GitHub actions is a CI/CD platform built into GitHub. Essentially, it allows you to set up tasks related to your code, and have them run automatically whenever you like.
The possibilities of what you do and how you schedule it are basically endless! You can automate when actions take place either by time (e.g. once an hour) or based on another action taking place (e.g. every time you push code changes up).
The task that is automated can also vary massively; essentially you can run anything which can take place on a virtual machine, so doesn’t need access to data, files, etc that are only held locally. You can do things like:
Knit a markdown document every time you push a change, which automatically produces and publishes the html report to GitHub pages
Run a webscraping process daily and save the data as a CSV into your repository
Run unit testing on code or packages every time you make a change
Create digital infrastructure using Terraform and build it every time a change is made
Examples of Actions at DfT:
7.9.2 How to set up your own actions?
Actions can range from relatively simple to set up to incredibly complicated!
Essentially, for every Action you need an associated yaml file. This is a text file which tells GitHub what processes to follow and in what order; this is stored in your .github/workflows folder so GitHub can find it.
There are existing free (and some paid for) actions that you can make use of online; e.g. the action to build a Docker instance with R and all required R packages already exists. You can call specific pre-built actions inside your yaml file to make the whole process easier.
For more complex Actions, you may need a whole range of other files to make this possible; from Docker instances, nojekyl files, or package management.
An example yaml file for a multi-step Action is shown below; you can also view this action in situ if you like.
## This specifies when the process runs: in this case, every time you push or pull code
on: [push, pull_request]
name: CI-CD
## This sets the virtual machine that the action runs on (in this case an Ubuntu Linux machine)
jobs:
CI-CD:
runs-on: ${{ matrix.config.os }}
name: ${{ matrix.config.os }} (${{ matrix.config.r }})
strategy:
matrix:
config:
- {os: ubuntu-latest, r: 'release'}
## These steps are the recipe that the action follows to perform the task you've specified
steps:
## This action checks out a copy of your GitHub repo to the virtual machine
- name: Checkout repo
uses: actions/checkout@v2
## These set up pandoc and R and install libraries
- uses: r-lib/actions/setup-pandoc@v2
- name: Setup R
uses: r-lib/actions/setup-r@v2
with:
r-version: ${{ matrix.config.r }}
use-public-rspm: true
- name: Install and cache dependencies
uses: r-lib/actions/setup-r-dependencies@v2
## This process builds a bookdown site from an Rmd file
- name: Build site
run: |
bookdown::render_book("index.Rmd", "bookdown::gitbook")
shell: Rscript {0}
## These steps check to see if the site is the live version, and if so deploys it to GitHub Pages
- name: Upload built site artifact
uses: actions/upload-artifact@v1
with:
name: site
path: _book
- name: Deploy to GitHub Pages
if: github.ref == 'refs/heads/main'
uses: JamesIves/github-pages-deploy-action@4.1.4
with:
branch: gh-pages
folder: _book
Once you’ve created the yaml file, you can push it up and GitHub will do the rest! After a short delay you can watch the Action deploy in the Actions tab, it’ll follow the yaml process you set out like a recipe, and will return either a green tick for success, or a red cross (and error log) for a failed action.
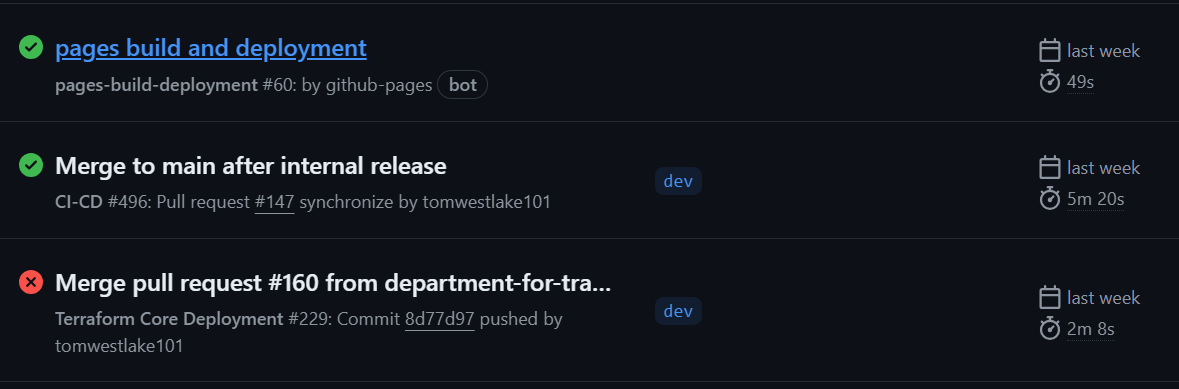
Keep an eye on the number of minutes your Action runs for, as they can rack up quickly. Our organisation has a number of minutes available per month, and once those are gone we can’t run any more actions for the month! If you have an Action that runs for more than 5 minutes at a time, or you plan to run more than once per day, message my team to check that it won’t be a problem.
It’s not unusual for it to take half a dozen attempts to get your first action working, but once it does it can be a massive timesaver!
Reach out for help creating your first action, we love to support on stuff like this!
7.9.3 Exercise (to try later)
- Navigate to https://github.com/department-for-transport/intro_R/blob/main/.github/workflows/deploy-bookdown.yaml and take a look at the format of the yaml here. How does each line work?
- Make a github actions folder in your own fork and copy the yaml over into it.
- Adapt the content to match your repository to knit the Rmd automatically and release the result to GitHub Pages every time you push to the repo
- Use the automated error reporting to debug what you are doing, and fix the problems
- (Optional) Have a little cry because this stuff is really hard
7.10 Secret Easter Egg: your GitHub home page
There’s an Easter Egg in GitHub! You can create a nice little landing page for your personal GitHub account, including links to stuff you find useful, a list of your repositories, your CV, or anything else you want to easily direct people to. Here is an example of mine.
7.11 Feedback
This concludes the intermediate GitHub course. Please complete the feedback form to help us improve your experience of completing a DfT coding course.