Chapter 8 GitHub Technical Lead Training
This chapter is primarily aimed at providing training for GitHub technical leads, who are required to take a leading position in ensuring that their code is shared on GitHub in a responsible way, particularly when considering making their code open source and publicly available.
Rather than exercises, this advanced course focuses on discussions around best practices for code sharing, governance, and security considerations.
8.1 Session aims
- introduction to open sourcing
- data security on GitHub
- secret security on GitHub
- controlling access and visibility
8.2 When is a technical lead required?
You must have a GitHub technical lead associated with any repository which is open to the public and published under the core department-for-transport GitHub organisations (this includes the public and external variations).
For all other repositories, it is not mandatory to have a technical lead associated with the project, but it is recommended. The admin of any repo can carry out a range of actions, some of which are destructive (e.g. deleting the repository and all its contents) and cannot be reversed. It therefore makes sense there is at least one person linked to the repo who understands GitHub best practice and can ensure it is being followed.
This is particularly important when repositories are shared with external collaborators, who may have varying levels of confidence in using GitHub. Where this is the case, there must be at least one admin associated with the repo who is part of DfT and has sufficient technical capability to ensure external collaborators are adhering to security and best practice standards. It is strongly recommended that this admin has attended the technical lead training as a result.
8.3 Considering open source code
Open source code refers to code which is made freely available to anyone, allowing them to view, modify, and distribute the code without restriction. In DfT, open source code is published in public-facing GitHub repositories, which makes it easy for any interested party to view, copy and build upon the code you have written. By default, all DfT repositories in GitHub are initially internally-facing only. To make your code publicly available, there are a number of technical and security considerations you need to go through first, which we cover in this course.
8.4 Costs, benefits and risks
Making your code public-facing has a number of advantages for both your users and your own team. This can include promoting transparency and reproducibility in analysis, allowing others to review and test your code, and improving efficiency by allowing other analysts to reuse your code.
On the flip side, open sourcing can also have a number of costs. Fundamentally, it requires you to maintain code to a suitable standard to be viewed by the general public at any time. This means you will need to put in extra effort to consider whether any part of your work contains sensitive information about your analysis, your data, or our digital systems, or is of poor enough quality to undermine trust in the work you are doing.
Most crucially, there are a number of risks which are introduced to your analysis when you make the decision to make your repository public. As technical lead for that repository, you need to be confident that you have considered and mitigated for all of these before proceeding to make your code public:
Making code open source can increase the risk of sensitive and security-related information being shared publicly.
Similar to security vulnerabilities, open sourcing code increases the risk of private or pre-release data being shared more widely.
Making code open source may reduce public trust in our analysis if the code contains errors or produces results which do not align with published figures. It is important that open-sourced code is of appropriate quality.
Once code is open sourced, it will require ongoing maintenance and support to ensure code remains current and appropriate to the analysis being conducted.
Making your code base public goes beyond the code itself. You will need to ensure your documentation and your development within GitHub, including comments, issues, pull requests, are ready to be made public too.
Before making anything public, you should always consider whether it is valuable, practical, and sustainable to make your code available in an open source manner.
8.5 Things that don’t belong on GitHub
8.5.1 Securely storing secrets
Secrets are defined as highly confidential bits of information that grant people access to data or information. These are most often things like passwords, API keys and PAT tokens. Accidentally providing secrets to people who should not have access to them can expose the department to security risks, costs, and reputational damage.
The most important thing to note is that you should never store secrets written into your code. This is true irrespective of whether that code is stored on GitHub or not; keeping your code in a private repository or a folder within a shared drive is not a get-around for storing your secrets appropriately.
As an analogy, you can think of your code containing secrets as the equivalent of your credit card information. Putting it into a public GitHub repo is like posting your credit card information directly onto a public social media site such as Twitter. Bad actors are actively trawling for this information, and it will (pretty much immediately) be stolen and used for nefarious purposes.
Choosing to store that secret-containing code in a private repo or shared drive is the equivalent of putting your credit card information on your friends-only Facebook profile; you’re trusting that everyone who can see it won’t accidentally use that information incorrectly, or share it more widely, and that you won’t accidentally share it further yourself. It’s not immediately damaging, but it’s an accident waiting to happen.
Secrets should always be stored separately from the code they relate to; this separation makes it harder to accidentally share those secrets bundled up with your code. In addition to this, safe ways to store your secrets depend on the coding package you are using.
For example, in R, you can:
Save the secret as a local environmental variable
Use a package which can securely encrypt an access token
Make the code request the secret every time as part of the run process
If you’re not sure the best way to store secrets in your chosen coding language or file type, find out before writing the code (and definitely before storing it on GitHub). You can get advice from the CRAN network if you have any concerns.
8.5.2 Data security on GitHub
Simply put, GitHub is not designed to be a storage location for all of the data used within your project. The default should always be that no data is ever stored on GitHub. Similar to secrets, often data can be highly confidential information which would be professionally damaging or costly to the department if it was accidentally shared more widely; imagine the issues associated with sharing e.g. financial information on a public repository.
In addition to this, GitHub is a worse place to put all of your data in comparison to our normal file/data storage locations, for a range of reasons:
- It doesn’t have the same level of security.
- It is slower to upload and download
- It doesn’t have sufficient space for large files
- It encourages bad practice and makes accidental data leaks more likely
- Tracking changes is limited to only a few file types
Note again that this applies to both public and private repositories; accidentally pushing data to the wrong repository and accidentally changing the visibility of repositories containing data are two of the most common ways to leak data by mistake.
Unsurprisingly, there are a wide range of better storage locations for your data available to you:
Storage in a cloud bucket
Use of a database (either cloud-based or local)
Storage on a shared drive that people can access with the correct permissions
Pulling published data from an API/online location directly
8.5.2.1 Exceptions to the rule
Unlike secrets, there are some limited and specific circumstances when it might be appropriate to store some data in your GitHub repository. This is only the case if all of the below points are true for the data:
It is a small file (a few MB in size as a maximum)
It’s data that you would be happy to share with anyone in the world (i.e. already published or widely available)
It is not sensitive in any way
It is stored in a format that GitHub can track changes to (e.g. CSV) and you need to make use of this version control feature
There is no better alternative place to store it because of the way the data needs to be used (e.g. not just because you don’t have permissions to the shared drive location you should be using instead)
The most common examples of this are data provided as part of a public package, and small lookup tables of publicly-available information that update regularly and you need to share with everyone who runs your code.
And to reiterate, this is a rare circumstance, and generally GitHub is not an appropriate location for data storage. If in doubt, don’t put it on GitHub!
8.5.3 Storing other things on GitHub
Of a lesser security concern are absolute file paths for locations of code and data; while these don’t present any specific security risk, they do allow people to build up an idea of how we store data, and present a maintenance dependency. Additionally, for code which is made public, this means anyone trying to run the code without access to DfT systems will return an error, often without explanation.
For published code, you should store any database, shared drive, etc locations as local environmental variables, instead of in the code itself. For internal-only code, it is fine for your project and code files to contain this type of information.
8.6 Editing .gitignore files
8.6.1 What is a .gitignore file?
GitHub includes by default a .gitignore file; this is an internal admin file which tells Git which files it shouldn’t look at when tracking. You can think of each line below as being a different “rule” which causes git to ignore a different file type.
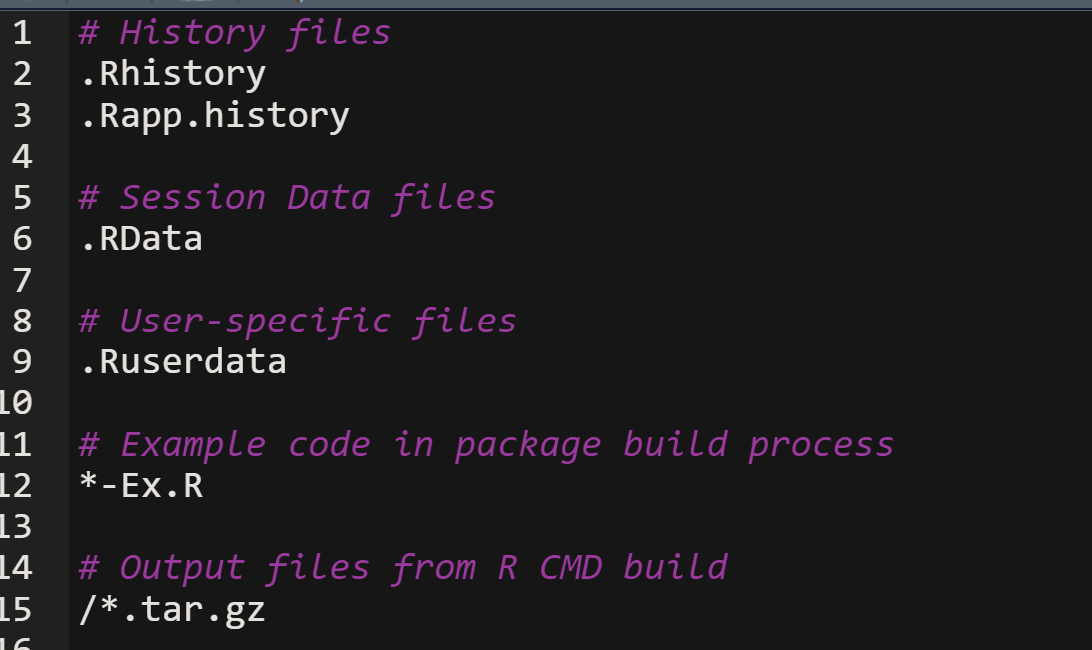
Git uses pattern matching when following these ignore rules. This means you can specify files by name, or also by:
- A string they contain
- The folder they are stored in
- Their file extension
Any file which is included in a .gitignore rule isn’t tracked. This means that changes aren’t recorded by git, and it’s not included in any version control features. This also means that the file itself can’t be pushed to GitHub.
Files which are included in the .gitignore rules can still be uploaded and used in your local version of the project, but they won’t be included when anyone else clones the project.
8.6.2 What files would you want to ignore?
By default, a .gitignore is often generated by GitHub, and contains a minimum number of rules that cover system files related to the language you’re coding in. For R, this will be things like .Rproject, and Rdata files. Special project types like bookdown or package builds come with longer .gitignore lists relevant to the type of files found in those projects.
The analyst_template template repository on the DfT GitHub comes with an extensive .gitignore designed to prevent accidental sharing of files and data by analysts. This includes:
- Data files such as CSVs, xlsx files, etc
- Images such as png and svg files
- Outputs such as word and html documents
If you are not familiar with creating your own .gitignore from scratch, this is a great place to start.
Regardless of what your starting point is, you should always configure your .gitignore to avoid accidental upload of:
- Data
- Secrets
- System files
- Outputs such as reports or charts
8.6.3 Setting your .gitignore
Editing your .gitignore is the same as editing any other plain text file. You can open it either directly within your local repository, or within GitHub, and add details of any files you don’t want to track. Each rule should be added to a separate line.
You can add rules to exclude any files that you like, either individual files or classes of file, as the .gitignore can use pattern matching. It is always preferrable to exclude an entire file type or folder rather than files by name; this prevents situations where files are renamed and accidentally uploaded.
8.6.3.1 Examples of adding rules
- Adding specific files (not preferred)
Use the whole pathname to a specific file
e.g. secret/my_data.xlsx
- Adding a file type
Use a wildcard (*) followed by the file extension
e.g. *.xlsx *.csv *.html
- Adding a whole folder
Give the name of the folder followed by a slash and wildcard
e.g. Data/* Outputs/*
8.6.4 Adding exceptions
There are always exceptions to blanket rules! Sometimes you will want Git to track files which go against the rules you’ve created, e.g. track one file in a folder, or have one csv which is trackable.
For security reasons (and admin simplicity), it’s always better to blacklist everything then add a single exception for a specified file, than blacklist individual files. This means that if you upload a new file, or change the name of an old file, the default is to “fail safe”.
To add an exception to an existing rule, add a new exception to this rule by:
- Providing the specific path or pattern you want to track, but preface it with an exclamation mark
!
Examples:
*.xlsxand!my_file.xlsxonly tracks one xlsx file (my_file.xlsx), all others are ignoredData/*and!Data/lookup.csvtracks the lookup.csv, but ignores everything else in the Data folder
Important note
.gitignore files are order-specific, and if two lines conflict with each other, the second of the two will overwrite the first.
For example, providing the two rules *.csv and !*.csv in this order would allow any CSV to be uploaded (exception overwrites the rule). Whereas providing !*.csv and *.csv in this order would allow no CSVs to be uploaded (rule overwrites exception).
8.6.5 For discussion:
Take a look at the gitignore here: https://github.com/department-for-transport/transport_modes_table/blob/dev/.gitignore
- What exceptions have been added?
- What risks do these present?
- Is there a different way this could have been done? Which would be your preferred approach?
- What would have happened if the order of the .gitignore rules *.xlsx and !Templates/publication_template.xlsx were reversed?
8.7 Controlling repository access
When managing GitHub repositories, you can control the access rights that other people have to your code in two ways; by limiting your repository visibility, and by controlling your collaborators list.
8.7.1 Different types of repo visibility
Any code relating to work done within DfT should always be stored in an organisational repo (one owned by department-for-transport). Code should never be stored in a repository owned by the individual, as these repositories have fewer access and security controls.
Organisational GitHub repos come in 3 flavours:
Visible only to people who have specifically been given access (and the repo owners).
Making a repository private is not a substitute for following any of the security rules, and does not mean you can store data or secrets in it. Private repositories also limit the ability for others to share and learn from the code you are writing, so are generally discouraged except for a few specific instances:
- Your repository is related to a pre-publication statistical release and holds content which should be restricted to the pre-release access list only (e.g. descriptive text or notes that gives an indication of the direction of movement of statistics).
- Your repository contains analysis related to policy or operational areas which need to have restricted visibility.
Visible to anyone within the DfT Enterprise organisation, but can only be modified by people you specify. This visibility setting is appropriate for the vast majority of coding projects within DfT, and is recommended as the default.
Visible to anyone in the world, but can only be modified by people you specify. Making a repository public can only be done where all of the following criteria are met:
- The project lead has determined it is appropriate for this code to be shared with the public, after carefully considering the risks and benefits
- A technical lead is associated with the project and is confident in their ability to review the code for any security or reputational risks associated with it
- The code is moved to the department-for-transport-public organisation, which is the only place where new public repositories can be created
You can set your repository visibility when you first create it, but cannot change the visibility for an existing repository without contacting an organisational owner, who can change it for you.
8.7.2 Different access rights
Inevitably, the people who need access to your repositories will change over time. As a repository admin, you have the ability to remove people, and also to add anyone who already exists within the DfT enterprise system. You cannot add external collaborators or people without a licence.
When giving repository access, it generally makes sense to use a GitHub Team whenever possible. You can create a team consisting of all your team members, and grant access to repositories in bulk, giving everyone in your team e.g. write access to all of your repositories. This means that when someone leaves or joins your team, you can change their access rights across every repo in a single step.
On top of this, you can also grant people individual permissions if, for example, they’re collaborating on a single repo with you, or they need admin rights for one repository. If someone already has team-based rights, you can’t grant them lower rights individually, only elevated permissions (e.g. if your team has write permissions, you can’t grant someone in the team read-only rights).
The three access permission levels you will use in your projects are:
Allows you to view the repository code, issues, and pull requests, without being able to make any changes. This is the default level of access everyone in DfT has to your internal repositories.
Allows you to view, clone, and make changes to the repository content, including being able to edit code, create branches, and create, edit, and delete issues and pull requests.
Full control over the repository. As well as write access to all content, can manage collaborators, change repository settings, and even delete the repository.
You can choose to set your collaborators repository permissions to whatever is appropriate for the work they are carrying out (this is true for both DfT and external collaborators). However, you should ensure that:
this is the minimum level of permissions they require, you should not give admin permissions to everyone just because its “easier”
they are technically competent enough with GitHub not to cause problems with the repo due to the permissions level they have (e.g. admins can permanently delete an entire repo and its contents, do you trust the person not to do this accidentally?)
8.7.3 Destructive actions on GitHub
By the nature of version control, GitHub is designed so there is very little you can do to cause permanent damage. Accidental commits, pushing, pull requests, and even deleting branches can all be easily undone. Primarily, you should reassure members of your team that there is virtually nothing destructive they can do on GitHub, and they should not be afraid to experiment and make mistakes.
The only exception to this is if you grant someone admin level permissions to a repository. This then grants them the ability to go to the danger zone of the repo:
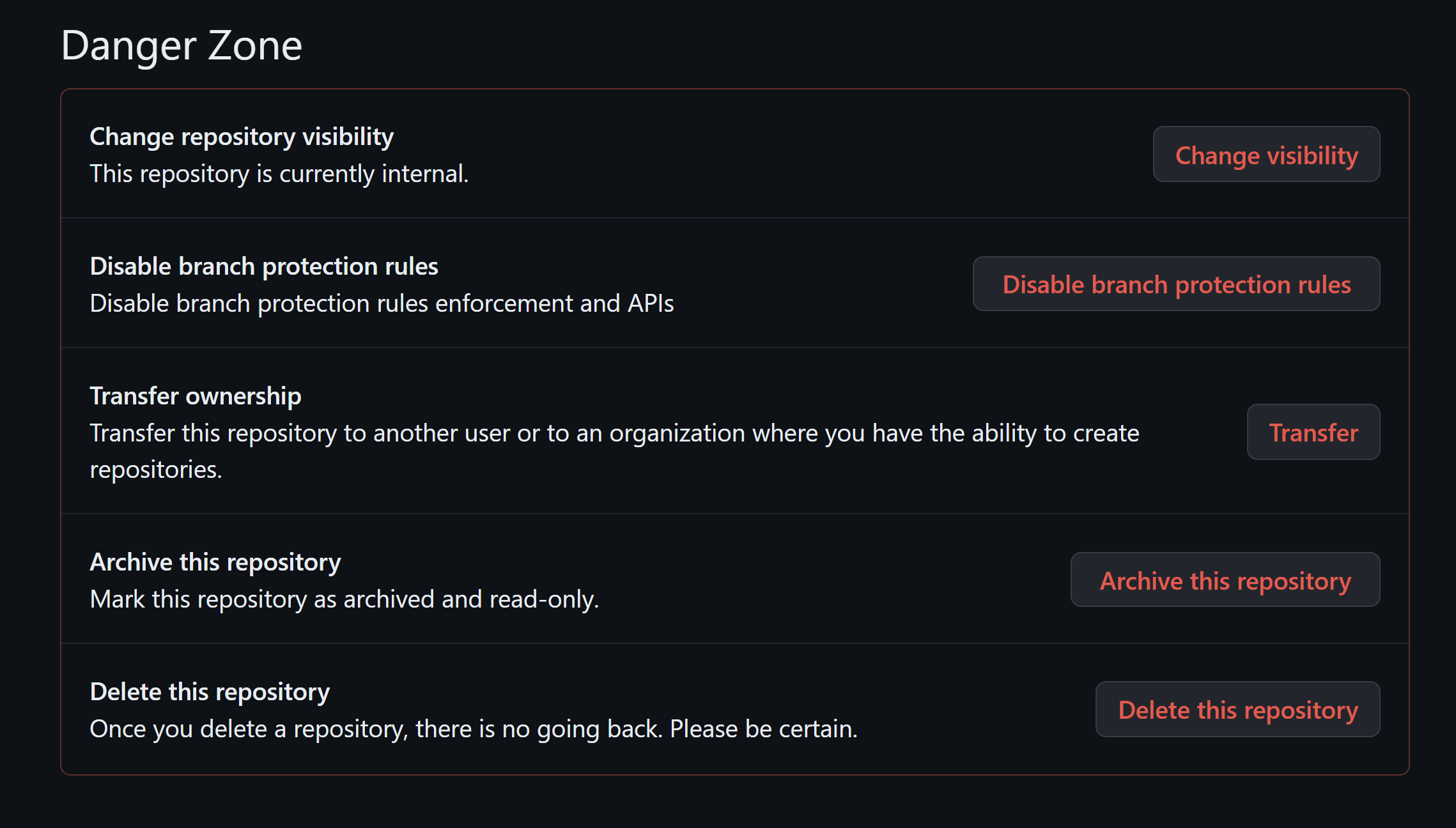
As you can see, clicking on these buttons can lead to permanent and destructive actions including deleting the entire repository, transferring it to someone else’s ownership, or accidentally making it public.
You should only ever make someone an admin on a repository if you are confident they fully understand the damage they can cause by clicking in this section, and will only ever do so with your agreement.
8.7.4 For discussion:
Your line manager asks you to add them as a collaborator to your repository. What access permissions do you give them?
You have a repository associated with a report you produce annually. What considerations do you think about when deciding what visibility this repo should have?
8.8 Reviewing code for security
Important note
The guidance in this section assumes you are performing a review ahead of making a repository fully open to the public. Most of this advice is still pertinent to repositories which are internal only or private (e.g. secrets should never be stored in code). Where guidance is not relevant to internal-only repositories, this will be indicated, otherwise assume that it is relevant to all repos.
As a technical lead, you have the responsibility to check that your repository is secure and doesn’t contain any data or secrets. You won’t be expected to review every single commit or pull request yourself, but you should promote best practice and put controls into place to ensure that code is always reviewed before being merged.
8.8.1 When should a security review happen?
At a minimum, you must do a thorough check of all the code when changing your repository visibility (e.g. from private to internal or internal to public).
As best practice, you should be regularly checking that there are no unexpected secrets or files uploaded to your repo, and speaking with your team to resolve this when you find any. To facilitate this, your team should be using a GitHub workflow such as Gitflow, which will allow you to see when and how changes were made, and prevent them from being merged across multiple branches without review.
Below, you can see the process that a project-lead should go through when considering whether to make a GitHub repository public. You may be involved at an earlier stage, but you are only required to step into your capacity of technical lead and perform the review once the project lead is satistified that publishing the code is in the best interests of the team and the public, and can be maintained long-term.

8.8.2 What should you do in a security review
The aim of this review is to identify any issues which could cause a security concern, either a cybersecurity risk (e.g. sharing login credentials), a data security risk (e.g. including an unpublished data file), or a reputational risk. This review can be conducted by any analyst who has undergone this training and feels confident in their ability to identify risks in the language the code is written in. If possible, you would be someone associated with the project and who has not written the code yourself.
If you are not sure whether you have identified a security concern in your code, you can contact a member of the StatsAID team to discuss your concerns.
In situations where a security breach could cause significant reputational or operational damage to DfT, you should contact the Digital Information and Assurance team for an expert code review alongside your own code review.
8.8.2.1 What to look for
At a bare minimum, you should ensure that the code does not contain any of the secrets or data as covered earlier in this chapter. This is anything that would permit someone access to a system, software, or any data which is not already published.
For repositories which are being made public, you should also ensure the repository does not contain any information such as:
processes behind the code which may cause security concerns (e.g. a comment saying “this section doesn’t work since the local security certificate changed to XYZ”)
information which may allow readers to infer (either correctly or not) information about future DfT plans or policy (e.g. a repository looking at the hypothetical impact of pedestrianising the M1 on travel times)
comments which are in breach of the CS code or professional standards
An edge case is code is pertaining to content governed by pre-release access rules (e.g. official statistics), which is fine to be made public however cannot be made public ahead of its release date. You can find specific guidance on publishing code like this here.
8.8.2.2 Where to look
Consider that on publishing, all aspects of your repository will be visible. This means that any security review should check the code and all comments throughout, but also:
- Commit messages
- Issues and PRs, including any comments
- GitHub workflows (see appendix 2 for further details)
- Project boards
- READMEs and wikis
All of these should be checked for everything mentioned above!
You should consider using a checklist to ensure you have checked both the what and where of checking your code. A good example of one is available here. You can upload this file to your repository to maintain an audit trail of how and when this security check was performed.
8.8.2.3 How to look?
There is an expectation that as part of this, yes you will need to read through every single file, commit, etc to check for the above. This can be a mammoth task if your repository has gone through a number of iterations and you’ve been brought in at the last stage.
The first thing to consider is whether you can transfer your code into a new public repository, rather than transferring ownership. Doing this means that your commit, issue, PR, etc history will be reset, and anything prior to this point will not be made public. This is a good way to ensure only the code, comments, and documentation will be visible to users, but does remove a valuable piece of the development process (especially if you’ll only be working out of the public repo moving forward). However, this is the best option if there are too many commits or changes for you to practically ensure that they all meet the standards required for public viewing.
The easiest way to do this is to create an entirely blank repository, and upload copies of your code files to this as a single bulk upload.
In addition to this, there are a few ways to quickly search for and identify significant problems in your code as a priority. To note, these are not a substitute for reading through all of the code, you are going to have to do that at some point!
Quick ways to find problems in your repo:
Look for data files, such as CSV and xlsx files. You can search for these easily by file extension in GitHub or your IDE.
Check any CI/CD processes in GitHub Actions against appendix 2 to quickly identify known risks
Try adding dummy data to see if upload is possible; if you add a dummy csv, xlsx file or html document, does Git track this file?
Search for secrets: again in GitHub or your IDE you can search across a whole project. Search for key words like “pass”, “key” or “token” to find secrets, or look for common strings in passwords (e.g. GitHub PAT token strings start with “gh”).
Check points of data entry and exit: look at the code which moves data in and out your project, as these are often weak points which require secrets to access.
Look for email addresses: use search tools to look for “@” symbols across the project to pick up personal email addresses (and likely other personal details!)
You can search commit messages, issues, etc in the GitHub search as well, try using all of the above searches to spot issues in these too!
8.9 The DfT public repository
Once you have completed all of the above steps, actually making your code open source is a very simple process!
8.9.1 Create a new repository
You can request access to the department-for-transport-public organisation from your ITFP upon completion of this training. This is an entirely separate DfT organisation, where all of the public repos are kept. Here, you will have permissions to create a new repository with public visibility, or change the visibility of an existing repository to public.
8.9.2 How should you add collaborators?
You can add collaborators to the repository on this organisation as external collaborators with write access or lower. Admin permissions are restricted to those who have completed this training. If you will be doing development work within the public repository, it is important that your collaborators understand all code in this repository is public, and will be visible as soon as they push. Whether or not they would like admin permissions, it is good practice that all collaborators on a public repository have attended this training within 6 months of being added.
8.9.3 How should you copy code over?
As mentioned above, there are two main ways you can bring your existing code into a new public repository.
This is technically quick and easy, but requires meticulous review of the repo content. You can transfer ownership of the repo from department-of-transport to department-of-transport-public, and then change the repository to public visibility. This preserves the repo exactly as it is, but does mean you’ll need to thoroughly review every commit for potential issues. Not for the faint of heart, or a repo with more than a handful of commits!
This option is essentially the opposite; more technically involved, but requires only a single review of the code in its current state. You can create a blank public repo, and download a copy of your old repo files as a zip file. This can then be uploaded to the new repo, which gives you a blank slate history-wise. This is much more realistic to review for security reasons, but does mean users miss out on seeing the prior development work.
8.9.4 How should you work moving forward?
You will want to consider how you manage the original and public repositories moving forward to avoid confusion, but also to ensure that content is not shared publicly if it is inappropriate for you to do so. You can either:
Do all development work in the public repository: this is appropriate if your code does not pertain to content published under pre-release access rules, and everyone in your repository is confident they know what should and should not be shared into a GitHub repository. In this instance, you can maintain a single, public repository relating to this work.
Do all development work in an internal repository, and only share the code periodically into the public repository. This is more appropriate for work which does not meet the above conditions, and you will need to review it before sharing each time.
8.9.5 For discussion:
- Check out these repositories for the transportverse and road safety statistics linking code. Which maintenance approach do you think these two repositories should have taken?
- Do you have any concerns about conducting security code review?
8.10 Summary and Feedback
This concludes the GitHub Technical Lead training. Please complete the feedback form to help us improve your experience of completing a DfT coding course.
8.11 Appendix 1: How does this apply to external repositories?
There is a third type of repository which is not discussed in this chapter in detail; external repositories. These are repositories managed as part of the department-for-transport-external organisation, and are used for collaboration with external partners which is not publicly visible.
If you are interested in setting up an external repository, you should contact the StatsAID team for guidance, but there are a few salient points you should consider:
Not all considerations relevant to public repositories are pertinent to external repositories, but you should still follow the same rules as internal repositories, and seek confirmation of which public-repository considerations are relevant. In particular, you should ensure that a technical lead conducts a review prior to sharing to ensure the repository does not contain any secrets or personal information.
External repositories only ever have one visibility setting; private. This is to avoid cross-sharing of repositories with external partners, and to ensure that all code shared is secure.
You should consider whether it is most appropriate for a repo managed between yourself and an external collaborator to be stored in the department-for-transport-external organisation, or whether ownership should sit with your external collaborator’s organisation. This will depend on the nature of the work, the level of security required, who the owner of the analytical outputs is, and the technical embeddedness of GitHub in your collaborator’s organisation.
Each external collaborator uses an Enterprise licence, so this is not appropriate for repositories you want to share with a large number of people.
You should ensure that all external collaborators are aware of the security standards when using our GitHub repositories, and have sufficient technical competency to adhere to them. You can share any DfT GitHub training materials with your collaborators to support their learning.
External repositories should always have at least one technically competent (ideally technical lead trained), DfT admin associated with the repository. It is not permitted to have repositories entirely owned and managed by external collaborators.
8.12 Appendix 2: Using GitHub Actions securely
Recently, GitHub Actions have become a surprising target for AI-driven security attacks. These attacks don’t necessarily target new or unknown vulnerabilities, but they are very good at acting at scale, so the number of attacks have ramped up. As a result, it’s really important to make sure that your GitHub Actions are secure. Luckily, that’s pretty easy to do!
8.12.1 Check 1: is this workflow public?
Is your GitHub Actions workflow associated with a public repo, or is it set to internal only or private? This isn’t an absolute fail-safe, but public repositories are more frequently targeted as they’re simply easier to get access to. Consider if your workflow absolutely needs to be public.
8.12.2 Check 2: What workflow trigger are you using?
The workflow trigger associated with your GitHub Action is what causes the action to run; this is often something like a pull request, a comment, or a specific manual trigger. The most common exploit target is pull_request_target and you must ensure that none of your GitHub Actions use this trigger. You should also think carefully about what triggers you are using generally; for example, anyone with write access can run a workflow_request trigger, so if it’s a repo with a large number of contributors that can carry out sensitive or destructive actions, this wouldn’t be a good choice of trigger. Triggers like pull request and push are generally safe.
You can read more about how pull_request_target has been used in recent cybersecurity breaches here.
8.12.3 Check 3: What permissions does your workflow have?
All workflows have the option to set what permissions they have to operate within their own repository. These allow your actions to perform tasks in your repository, but also are the permissions that could be given to a 3rd party in the event of a security breanch. As a result, it’s important that these are set explicity and appropriately to avoid the potential of high-level permissions being the target of an attack. As a result, these should always be set explicitly, e.g.:
permissions:
id-token: write
contents: readThey should always be tightly scoped, and write permissions should only be granted where required. It is good practice to ensure that Where write access is required, it is scope it to the job only, not the entire workflow, e.g.
YAMLjobs:
deploy:
permissions:
id-token: write
contents: read8.12.4 Check 4: What third-party actions are you using?
GitHub Actions allow you to reuse code written by other people. While this is extremely convenient, it means you are executing code that you do not control. In addition, tags setting versions of actions are changeable, meaning using v3 of someone else’s action doesn’t mean you’re using the same version day-to-day.
To reduce this risk, all third-party actions must be pinned to a specific commit hash (SHA). This ensures that the exact version of the code you are running cannot change unexpectedly.
#Secure example
YAML
uses: actions/checkout@8f4b7e9e8c8c2a0f7a0b123456789abcdef123456
#Not secure
YAML
uses: actions/checkout@v3
You should also always prefer actions maintained by GitHub or other trusted organisations, and avoid using actions from unknown or unverified maintainers, ensuring that any third-party actions you do use are from a reputable source and regularly maintained. You should also do a basic security check of the source code of any third-party actions, ensuring that you understand them sufficiently to know what they are doing and why, being particularly wary of third-party actions containing strings of “nonsense code” or calling to other third party actions themselves.
8.12.5 Check 5: How are you using secrets?
GitHub Actions workflows often need access to credentials in order to interact with systems (e.g. cloud platforms, data storage). These credentials are frequently targets for attacks, and should be used and stored securely.
GitHub actions should therefore never make use of long-lived credentials (e.g. PAT tokens, API keys, service account keys), and these should not be stored in repository or organisation secrets. Instead, use short-lived, automatically generated tokens, should be used, such as GitHub App credentials, OIDC or WIF. These approaches generate credentials dynamically at runtime, and automatically expire after use, which limits the impact if a token is exposed.
8.12.6 Check 6: How are your repositories secured?
Even if your workflows are correctly configured, the surrounding repository controls play a critical role in preventing compromise. Workflows should be treated as privileged infrastructure. To do this, changes to .github/workflows/* must always require review before being merged.
Branch protection rules should be enabled for key branches (e.g. main), and you should restrict pushing directly to main branch, ensuring changes are made by pull request with approval before changes are merged.
8.12.7 Check 7: How would you respond to an incident?
Even with strong controls in place, security incidents can still occur. Technical leads must ensure that their repositories and workflows are designed so that credentials can be revoked quickly and systems can be secured without delay. You should also know how and when to report potential cybersecurity breaches.