Chapter 2 What is reproducible analysis?
The concept of Reproducible Analytical Pipelines (RAP) was developed by the Government Digital Service. This aimed to combine the best practice and tools from data science with the reproducibility approach of analysis, to create a single automated process which generates analytical results in a way that can be replicated over and over.
The “pipeline” part of this refers to the idea that you should be able to create an approach which produces everything you need for a publication in a single, streamlined program. This goes from extraction of data, through data preparation and quality assurance (QA), to the final report. However, for most processes the real value in a RAP approach is the reproducible analysis part; making use of best practice and tools which ensure a minimum standard of quality in your work.
Throughout this book, we will refer to the idea of “reproducible analysis” to emphasise the fact that work does not need to be built into a single, completed pipeline in order to benefit from the application of RAP approaches.
2.1 RAP levels
If you’ve spent much time around RAP documentation, you’ll have almost certainly seen one or more versions of the “RAP levels” table below:
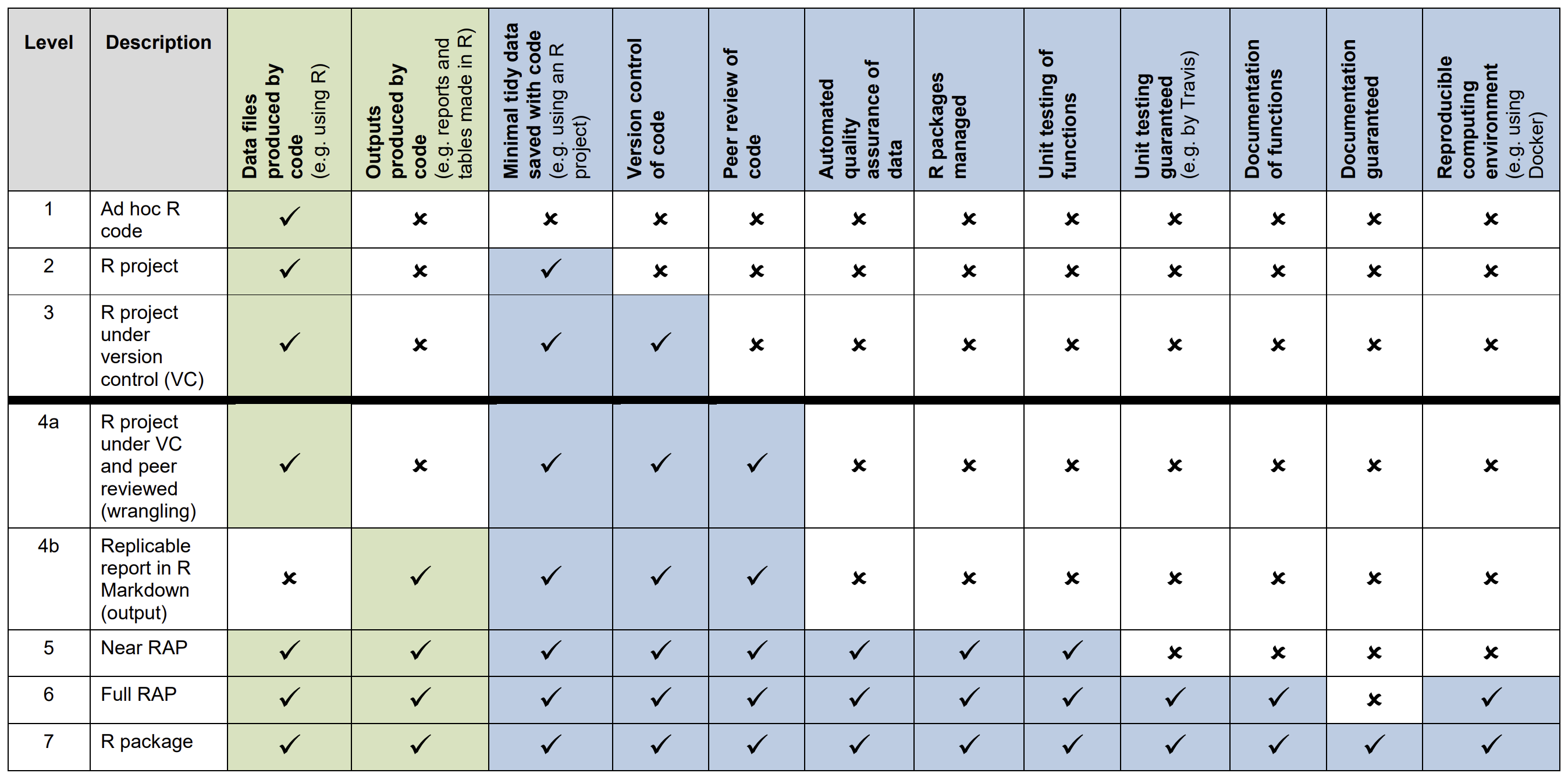
This table aims to outline the principle components of coding projects, and which of these are essential for a project to be considered reproducible. However, if you’re not coding on a day-to-day basis, many of these components can be difficult to understand! In the sections underneath, the aim is to outline in plain language the two most important levels and the required components for them:
2.1.1 Minimum standard for a reproducible coding project
Level 4 in the above table is what is generally considered to be the minimum requirements for a coding project to meet the standard of reproducibility. These are:
Code is used to produce the output of the project: Whether the project outputs a tidied dataset, publication tables, charts, etc, these are created using code. Products such as Excel, and proprietary software such as SAS or SPSS can’t produce products which meet reproducible analysis standards as they aren’t transparent, and can’t be effectively version controlled.
Tidy data saved with code: Your code extracts and cleans up your data ready for use in the next steps. There are no manual, user-input steps to produce the clean data.
Version control of code: You make use of Github during your project to track your code as it develops, which allows you to see the who, when, what and why of every single change made to your code.
Peer review: Distinct from QA, peer review of your code gets an expert to review the code you have produced to check it is efficient, well documented, meets best practice, and to highlight any weaknesses or problems in the code.
2.2 What a full reproducible analysis approach should look like
In addition to the above points, a project which fully adheres to reproducible analysis principles will include:
Automated quality assurance: Your project should include automated checking of the data it produces. Often this will be the most boring and repetitive aspects of QA; checking that totals match summed individual values, and that values match across different outputs. You can generate reports within your project to quantify and present the results of whatever QA checks you need to do.
Packages managed: This ensures that everyone who uses the project is using the same packages, down to the individual package versions, to avoid changes to libraries breaking your code. R has a package called renv which is easy to use, and will do this for you.
Unit testing: Unit testing takes functions that you create as part of your code and creates tests for them using example data, making sure they do what you expect, and don’t produce unexpected results now or in future. Unit testing can be tricky to write and automate, you can get support to do this by making use of the central DfT R packages in the
transportverse; either by using existing functions instead of writing your own, or submitting your own general functions to these packages, where an expert will help you write unit testing.Documentation of functions: When you check the help of any function in R using e.g.
?sum(), R will pull up a standard documentation file. You will want to add this type of documentation to any functions you write as well; again, this can be made easy by making use of the central DfT R packages.Reproducible coding environment: You’re in luck here! If you’re making use of Cloud R, this is already done for you.
It’s worth noting that some of the components of a full reproducible analysis project may be complex and time consuming to implement. Throughout this book, we aim to bring a sense of proportionality to creating reproducible analysis, and support you to make strategic decisions about which of these points are the most useful to apply to your own projects.